- Published on
Claude Code 自動驗證與自主開發:別再盯著 Agent 看了(2026)
Table of Contents
Claude Code 自動驗證(Verification)是指讓 AI agent 在寫完程式碼後,自己啟動應用、操作 UI 或打 API、驗證結果是否正確,失敗就自己讀 log 修正再重來 — 整個過程不需要人類介入。這是 Anthropic 在 2026 年 Code with Claude 大會上提出的核心開發模式,搭配平行化(Parallelize)和背景執行(Background Loops),讓開發者從「一直盯著 Agent 等結果」轉變成「丟了任務去做別的事」。
你用 Claude Code 的方式是不是這樣 => 丟一個 prompt,按 Enter,然後坐在那盯著它跑,看結果,手動去瀏覽器點一下確認,發現不對再丟下一個 prompt。
整個流程裡你就是那個瓶頸。不是 Claude 太慢,是你的鍵盤擋在中間。
2026 年 5 月的 Code with Claude 大會上,Claude Code 共同創辦人 Sid Bidasaria 直接點出了這件事。他的解法不是「更好的 prompt」,而是改變你跟 Agent 的互動模式 — 他稱之為 Stop babysitting your agents。
三個可以疊加的自主開發模式

來源:Code with Claude 2026 — Sid Bidasaria「Stop babysitting your agents」
| 模式 | 核心概念 | 你省下什麼 |
|---|---|---|
| Verification | 教 Claude 自己驗證產出 | 你不用手動測試 |
| Parallelize | 同時跑多個 Claude agent | 你不用排隊等 |
| Background Loops | 任務丟到雲端自己跑 | 你可以離開電腦 |
這三個模式是有順序的:Verification 是地基,沒有它後面兩個都是空談。沒有驗證能力的 Agent 跑再多個、再自動都沒用,只是更快地產出更多沒人確認過的 code。
這篇會從最核心的 Verification 開始拆。
Verification:讓 Claude 自己驗收自己的產出
開發瓶頸已經轉移了
大會上有一句話讓我印象很深:
寫 code 不再是慢的那一環。驗證它、review 它、協調它 — 這些才是真正的瓶頸。
有團隊導入 Claude Code 自動驗證流程後,三個月內 PR 產量從 500/週拉到 1,150/週,成長 300%。瓶頸從「寫 code」轉移到「review 和文件」— 這已經不是 AI 的問題了,是人類的頻寬跟不上。
你讓 Claude 寫 code 已經夠快了,但如果每次寫完都要你去瀏覽器手動確認、跑一次 API、肉眼看結果,那快也沒意義。
自動驗證迴圈
Claude 寫完 code 後不是丟回來等你驗收,而是自己走完整個迴圈:
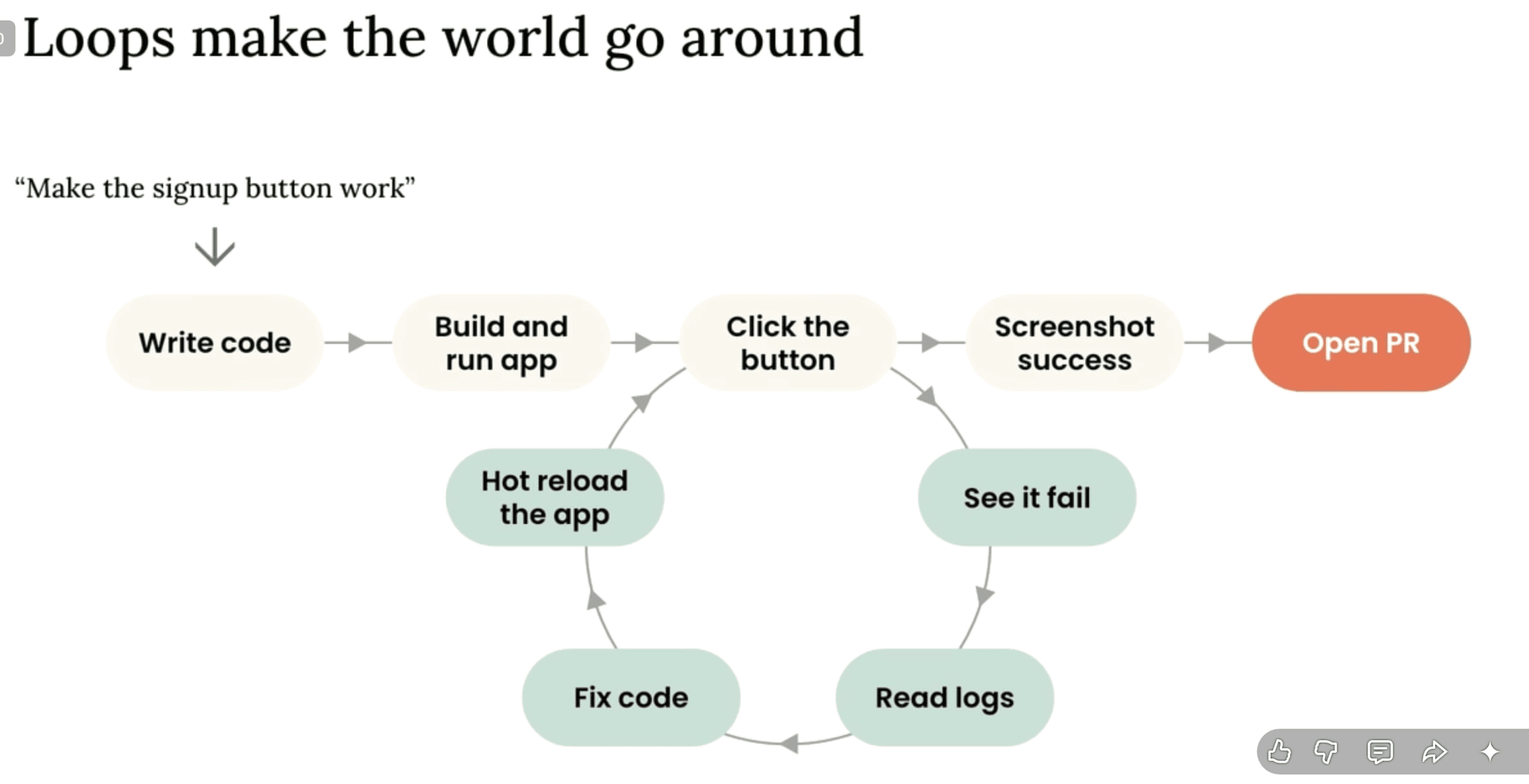
Loops make the world go around — Claude 的自動驗證迴圈
成功路線:Write code → Build and run app → 操作 UI 或打 API → 截圖確認成功 → Open PR
失敗路線:看到失敗 → 讀 log → 修 code → Hot reload → 再試一次
整個 loop 跑到通過為止,你不需要介入。Claude 的哲學是 Let the model cook — 讓它自己煮,你不用一直掀鍋蓋看。
Run → Drive → Prove → Unblock 驗證框架
Sid 把自動驗證拆成四個步驟,前端跟後端的做法完全不同:

Run → Drive → Prove → Unblock 前後端對照
用文字展開每一步:
| 步驟 | Frontend / UX | Backend |
|---|---|---|
| Run it | 一鍵起 dev server(pnpm dev) | docker compose up 或 make dev |
| Drive it | Claude-in-Chrome / Playwright 去點按鈕、填表單 | curl 打 API、hit health endpoint |
| Prove it | 截圖 before / after 比對 | 查 DB、讀 log、replay prod traffic |
| Unblock it | Dummy auth 繞登入、seed script 灌測試資料 | Structured log 讓 Claude 能 grep、加 log line 證明 path 有跑到 |
每一步都有明確的目的 =>
- Run:把環境拉起來,確保有東西可以操作
- Drive:去觸發動作,不是看 code 而是真的去用
- Prove:驗證結果真的發生了,不是「看起來沒報錯就算過」
- Unblock:預先移除讓 Claude 卡住的障礙(登入牆、空資料庫、讀不到的 log)
其中 Unblock 最容易被忽略,但它決定了 Claude 會不會中途卡住來問你。如果你的 app 一打開就要登入,Claude 不知道帳密就卡死了 — 所以預先設定 dummy auth 或 bypass,讓它能直接進到要測的功能。
Backend 自動驗證的三個層次
這是我覺得整場最實用的觀念,值得單獨拉出來講。大部分人讓 Claude 驗證 API 就是 curl 一下看 response,但這遠遠不夠。
假設你叫 Claude 寫了一個 order API:
curl -X POST localhost:3000/api/orders -d '{"item":"keyboard","qty":1}'
# => 200 OK, {"id": 42, "status": "created"}
200 OK,看起來沒問題?但 200 OK 不代表資料真的寫進 DB 了。可能 response 是 mock 的、可能 transaction 沒 commit、可能寫進了錯的 table。
所以 Claude 接著要做第二層 — 直接進 DB 確認:
docker exec postgres psql -U user -d mydb \
-c "SELECT * FROM orders ORDER BY created_at DESC LIMIT 1;"
不需要 MCP,本機的 Docker container 用 bash 就能查。
但還有第三層。你的 middleware 有個分支邏輯,某些情境應該走 A 路線而不是 B。curl 回 200、DB 有資料,但程式實際上走了錯誤的分支 — 這時候只有 log 能抓出來:
docker logs myapp 2>&1 | grep "order.created"
三層驗證對照
| 驗證層 | 工具 | 能證明什麼 | 盲區 |
|---|---|---|---|
| API 層 | curl | response 格式和 status code | 資料有沒有真的落地 |
| 資料層 | DB query | row 存不存在、欄位對不對 | code path 有沒有走對 |
| 程式路徑層 | structured log | 預期的邏輯分支有沒有執行 | — |
重點是三層要一起跑,單獨任何一層都有盲區。這也是為什麼光寫 unit test 不夠 — test 驗證的是邏輯對不對,但這三層驗證的是「真的跑起來之後,從 API 到 DB 到 code path 整條鏈有沒有通」。
Structured Log:讓 Claude 能讀懂的 Log 格式
Claude 要能 grep log 並自動判斷結果,log 格式就不能是給人看的 pretty print:
{
"event": "order.created",
"orderId": 42,
"path": "standard",
"ts": "2026-06-02T10:00:00Z"
}
而不是:
[INFO] 2026-06-02 10:00:00 - Order created successfully! ID: 42
前者 Claude 直接 grep "order.created" 然後 parse JSON 就能判斷,後者要靠 regex 猜格式,容易出錯。Sid 在演講中特別強調 — Structured logs Claude can grep 不是建議,是讓 Agent 自主工作的前提。
Log 存在哪?各環境對照
這是很多人忽略的問題。Claude 要讀 log,得先知道去哪讀:
| 運行方式 | log 在哪 | Claude 怎麼讀 |
|---|---|---|
| Docker Compose | container stdout | docker logs myapp |
| 本機 Node / .NET | terminal 或 ./logs/app.log | cat / tail -f |
| Linux Server | /var/log/ 或 systemd journal | journalctl -u myapp |
| Azure App Service | Azure Monitor | az webapp log tail |
| Vercel / Railway | 各自 dashboard | 接 CLI 或 MCP |
本機開發最單純,docker logs 就搞定。上了雲端才需要 MCP 或平台 CLI 介接。
如果你在 verify skill 裡告訴 Claude log 在哪裡、用什麼指令讀,它就不需要猜,也不會卡在「找不到 log」這種低階問題上。
把驗證包成 Verify Skill
手動跟 Claude 講一次驗證流程可以,但你不會每次都想重複「起 server → 打 API → 查 DB → 看 log」。Claude Code 的 Skill 機制讓你把驗證流程封裝成可重複使用的指令。

官方的 verification skill 範例與設計原則
實際的 verify skill 長這樣(以前端專案為例):
---
name: verify
description: 每次改 code 後自動驗證前端行為。改到相關 code 時積極使用。
---
1. pnpm run dev(前端 + 後端都拉起來)
2. 等 localhost:3000 health check 通過
3. 用 Claude Chrome MCP 打開 localhost:3000
4. 測試所有改到的功能,加上 $ARGUMENTS 指定的場景
5. 需要的話,用 log 比對行為是否符合預期
如果遇到障礙,找到解法並更新這個 skill。
Skill 設計三原則
- 不要太死板:寫「測試所有改到的功能」而不是列出每個按鈕。Claude 看得到它改了什麼 code,讓它自己判斷該測哪裡
- 讓它自我改進:最後那句「遇到障礙就更新 skill」是關鍵。Claude 在實際跑 verify 時會踩到各種坑(port 被佔、seed 資料不夠),它會自己把解法寫回 skill
- 明確提到工具:告訴 Claude 用 Chrome MCP、用 log。它手上有很多工具,但不提它不一定會用
Pro tip:用 Stop Hook 自動觸發驗證
在 Claude Code 設定裡加一個 stop hook — Claude 每次要結束工作時,自動問它「你跑過 verify 了嗎?」如果沒有,它會自己補跑。
這比你每次都記得說「跑完記得驗證」可靠太多了。人會忘,hook 不會。
Parallelize:多個 Agent 同時推進
第二個模式是平行化。你不需要一次只跟一個 Claude Code 對話。
實際的做法是同時開多個 session,每個做不同的事:一個在寫新 feature、一個在修另一個 bug、一個在跑 code review、一個在寫測試。
Sid 自己的日常是 4-5 個 agent 同時跑,用類似 tmux 的分割畫面管理。不是幾十個 — 大約就是一隻手數得出來的量級,但每個都在獨立推進不同任務。
關鍵不是「越多越好」,而是你的工作流裡有多少可以同時進行的事。大部分工程師一天要碰好幾個 PR、好幾個 issue,這些本來就是互相獨立的 — 只是以前你只有一個腦袋,只能排隊做。
平行化有一個前提 => 任務要獨立。不同 feature branch、不同模組、不同類型的工作(寫 code vs review vs 測試)。Claude Code 的 worktree isolation 可以讓每個 agent 在獨立的 git worktree 裡工作,避免改到同一個檔案打架。
Background Loops:丟了任務就走
第三個模式把前兩個推到極致 — 你連電腦都不用開著。
Claude Code on the Web 讓你可以把任務提交到 Anthropic 的雲端基礎設施。Claude 自己跑完整個驗證迴圈,完成後通知你。搭配 /schedule 指令還能設定排程,例如每天早上自動跑一輪 code review。
實際場景:
- 睡前丟一個 feature 需求,早上起來看 PR
- 把 CI 失敗的修復丟給 Claude,自己去開會
- 排程每天凌晨跑 dependency update + 自動測試
Verification 搭配 Background Loops 就形成閉環:Claude 自己寫 → 自己跑 → 自己驗 → 自己修 → 驗過了開 PR。你從「操作員」變成「審核者」— 只看最後結果,不管中間過程。
三個模式的疊加順序
這三個模式不是三選一,是層層堆疊的。順序很重要:
- 先有 Verification,Claude 才能自己判斷對錯
- 有了驗證能力,Parallelize 才有意義(不然開十個 agent 只是更快地產出十坨沒驗證過的 code)
- 前面都到位了,Background Loops 才能真正放手(因為你信任它會自己驗、自己修)
如果你現在什麼都還沒設定,就從 Verification 開始:寫一個 verify skill,加一個 stop hook。光這兩步就能讓你省下大量手動測試的時間,也是走向完全自主開發的第一步。
我的實作經驗
我在這個 blog 專案(Next.js + MDX)裡實際用了類似的流程:
- verify skill 會起
yarn dev,用 Claude-in-Chrome 打開頁面,確認文章渲染正常、Dark Mode 顯示正確、圖片有載入 - stop hook 確保每次改 code 都會自動跑
yarn lint和npx tsc --noEmit - 寫文章時開兩個 agent:一個寫內容、一個生成 SVG 圖片
最大的差異:以前寫完一篇文章要花 20 分鐘來回確認排版和連結,現在 Claude 自己確認完才提交。那 20 分鐘我可以去構思下一篇的主題。
FAQ
Claude Code 自動驗證和 unit test 有什麼不同?
測試(unit test、integration test)是在 CI 環境跑的,驗證程式邏輯對不對。自動驗證(Verification)是跑真的 app 然後去操作它,驗證「使用者看到的東西對不對」。兩者互補不是替代 — 你的 unit test 可以通過但 UI 是壞的,反過來也是。
Backend 驗證一定要用 MCP 連 DB 嗎?
不用。本機 Docker 起的 DB,Claude 直接 docker exec 進去跑 psql 或 mysql 就能查。MCP 是當你要連遠端 DB(例如 staging 環境)或需要透過 SDK 操作時才需要。大部分本機開發場景,bash 指令就夠了。
怎麼讓現有專案的 log 變成 Claude 能讀的格式?
最快的方式:把 console.log 換成 structured logger。Node.js 用 pino、Python 用 structlog、.NET 用 Serilog,輸出 JSON 格式,每個 log entry 帶 event 欄位。不需要一次全改完,先把你最常需要驗證的關鍵路徑 log 改掉就有效果。
Claude Code on the Web 跟本機跑有什麼差異?
功能一樣,差在執行環境。Web 版跑在 Anthropic 的雲端,不佔你本機資源,可以關電腦。用量計算方式和本機版一樣,包含在 Claude Pro / Team / Enterprise 的 Claude Code 額度裡。適合長時間執行的任務,例如大型 refactor 或跑整套 e2e test。
Verify Skill 該多久更新一次?
不需要排時程更新。Skill 裡寫了「遇到障礙就更新」,Claude 在日常使用中會自己累積修正。你要做的是偶爾看一眼 skill 檔案,確認它學到的東西是你認同的。如果某次驗證流程特別不順,也可以手動加一行提示避免下次踩同樣的坑。
相關文章
Anthropic 官方拆解長時間 AI Agent 的兩大失敗模式(context anxiety 與自我評價偏差),並用三代理架構 Planner / Ge...
2026-05-31
Claude Code ultrathink 使用教學 2026。一行提示詞觸發 high effort 深度思考模式,附最新 effort 系統說明、版本演進...
2026-03-29
GSD 處理上下文腐爛、Superpowers 防止 AI 偷工減料、Agent Teams 解決持續溝通的問題。三套工具不互斥,這篇教你根據任務性質隨時搭配。
2026-03-28